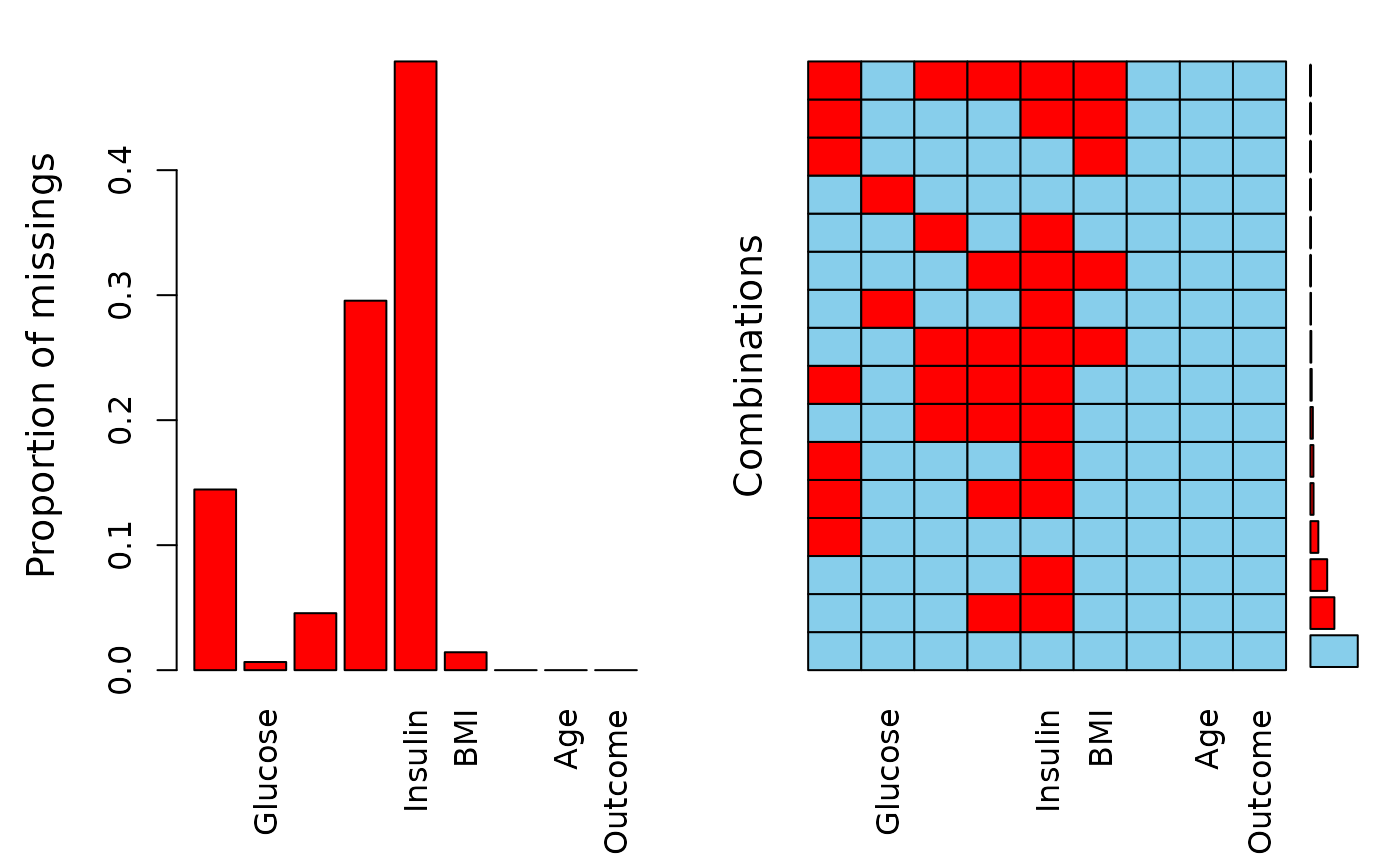
The datasets consists of several medical predictor variables and one target variable, Outcome. Predictor variables includes the number of pregnancies the patient has had, their BMI, insulin level, age, and so on.
Format
A data frame with 768 observations on the following 9 variables.
- Pregnancies
Number of times pregnant
- Glucose
Plasma glucose concentration a 2 hours in an oral glucose tolerance test
- BloodPressure
Diastolic blood pressure (mm Hg)
- SkinThickness
Triceps skin fold thickness (mm)
- Insulin
2-Hour serum insulin (mu U/ml)
- BMI
Body mass index (weight in kg/(height in m)^2)
- DiabetesPedigreeFunction
Diabetes pedigree function
- Age
Age in years
- Outcome
Diabetes (yes or no)
Details
This dataset is originally from the National Institute of Diabetes and Digestive and Kidney Diseases. The objective of the dataset is to diagnostically predict whether or not a patient has diabetes, based on certain diagnostic measurements included in the dataset. Several constraints were placed on the selection of these instances from a larger database. In particular, all patients here are females at least 21 years old of Pima Indian heritage.
References
Smith, J.W., Everhart, J.E., Dickson, W.C., Knowler, W.C., & Johannes, R.S. (1988). Using the ADAP learning algorithm to forecast the onset of diabetes mellitus. In Proceedings of the Symposium on Computer Applications and Medical Care (pp. 261–265). IEEE Computer Society Press.